
In this book, we conducted a customer segmentation, clustering, and prediction analysis using Python. We began by exploring the customer dataset, examining its structure and contents. The dataset contained various features such as demographic, behavioral, and transactional attributes.
To ensure accurate analysis and modeling, we performed data preprocessing steps. This involved handling missing values, removing duplicates, and addressing any data quality issues that could impact the results. We also split the dataset into features (X) and the target variable (y) for prediction tasks. Since the dataset had features with different scales and units, we applied feature scaling techniques. This process standardized or normalized the data, ensuring that all features contributed equally to the analysis.
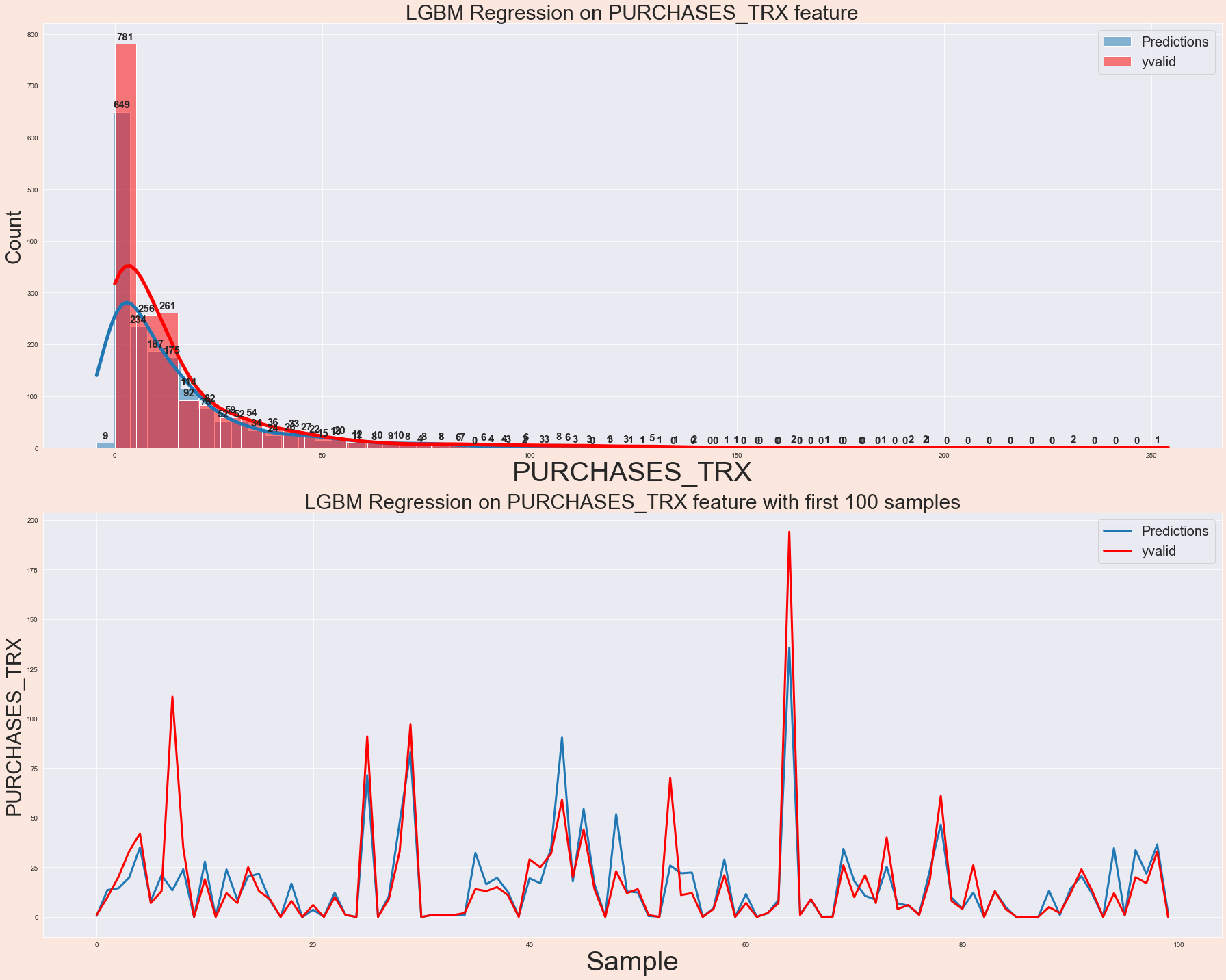
We then performed regression analysis on the "PURCHASESTRX" feature, which represents the number of purchase transactions made by customers. To begin the regression analysis, we first prepared the dataset by handling missing values, removing duplicates, and addressing any data quality issues. We then split the dataset into features (X) and the target variable (y), with "PURCHASESTRX" being the target variable for regression. We selected appropriate regression algorithms for modeling, such as Linear Regression, Random Forest, Naïve Bayes, KNN, Decision Trees, Support Vector, Ada Boost, Catboost, Gradient Boosting, Extreme Gradient Boosting, Light Gradient Boosting, and Multi-Layer Perceptron regressors. After training and evaluation, we analyzed the performance of the regression models. We examined the metrics to determine how accurately the models predicted the number of purchase transactions made by customers. A lower MAE and RMSE indicated better predictive performance, while a higher R2 score indicated a higher proportion of variance explained by the model. Based on the analysis, we provided insights and recommendations. These could include identifying factors that significantly influence the number of purchase transactions, understanding customer behavior patterns, or suggesting strategies to increase customer engagement and transaction frequency.
Next, we focused on customer segmentation using unsupervised machine learning techniques. K-means clustering algorithm was employed to group customers into distinct segments. The optimal number of clusters was determined using KElbowVisualizer. To gain insights into the clusters, we visualized them 3D space. Dimensionality PCA reduction technique wasused to plot the clusters on scatter plots or 3D plots, enabling us to understand their separations and distributions. We then interpreted the segments by analyzing their characteristics. This involved identifying the unique features that differentiated one segment from another. We also pinpointed the key attributes or behaviors that contributed most to the formation of each segment.
In addition to segmentation, we performed clusters prediction tasks using supervised machine learning techniques. Algorithms such as Logistic Regression, Random Forest, Naïve Bayes, KNN, Decision Trees, Support Vector, Ada Boost, Gradient Boosting, Extreme Gradient Boosting, Light Gradient Boosting, and Multi-Layer Perceptron Classifiers were chosen based on the specific problem. The models were trained on the training dataset and evaluated using the test dataset. To evaluate the performance of the prediction models, various metrics such as accuracy, precision, recall, F1-score, and ROC-AUC were utilized for classification tasks. Summarizing the findings and insights obtained from the analysis, we provided recommendations and actionable insights. These insights could be used for marketing strategies, product improvement, or customer retention initiatives.





















No comments:
Post a Comment