Kobo Store

The Applied Data Science Workshop on "Urinary Biomarkers-Based Pancreatic Cancer Classification and Prediction Using Machine Learning with Python GUI" embarks on a comprehensive journey, commencing with an in-depth exploration of the dataset. During this initial phase, the structure and size of the dataset are thoroughly examined, and the various features it contains are meticulously studied. The principal objective is to understand the relationship between these features and the target variable, which, in this case, is the diagnosis of pancreatic cancer. The distribution of each feature is analyzed, and potential patterns, trends, or outliers that could significantly impact the model's performance are identified.
To ensure the data is in optimal condition for model training, preprocessing steps are undertaken. This involves handling missing values through imputation techniques, such as mean, median, or interpolation, depending on the nature of the data. Additionally, feature engineering is performed to derive new features or transform existing ones, with the aim of enhancing the model's predictive power. In preparation for model building, the dataset is split into training and testing sets. This division is crucial to assess the models' generalization performance on unseen data accurately. To maintain a balanced representation of classes in both sets, stratified sampling is employed, mitigating potential biases in the model evaluation process.
The workshop explores an array of machine learning classifiers suitable for pancreatic cancer classification, such as Logistic Regression, K-Nearest Neighbors, Decision Trees, Random Forests, Gradient Boosting, Naive Bayes, Adaboost, Extreme Gradient Boosting, Light Gradient Boosting, Naïve Bayes, and Multi-Layer Perceptron (MLP). For each classifier, three different preprocessing techniques are applied to investigate their impact on model performance: raw (unprocessed data), normalization (scaling data to a similar range), and standardization (scaling data to have zero mean and unit variance).
To optimize the classifiers' hyperparameters and boost their predictive capabilities, GridSearchCV, a technique for hyperparameter tuning, is employed. GridSearchCV conducts an exhaustive search over a specified hyperparameter grid, evaluating different combinations to identify the optimal settings for each model and preprocessing technique.
During the model evaluation phase, multiple performance metrics are utilized to gauge the efficacy of the classifiers. Commonly used metrics include accuracy, recall, precision, and F1-score. By comprehensively assessing these metrics, the strengths and weaknesses of each model are revealed, enabling a deeper understanding of their performance across different classes of pancreatic cancer. Classification reports are generated to present a detailed breakdown of the models' performance, including precision, recall, F1-score, and support for each class. These reports serve as valuable tools for interpreting model outputs and identifying areas for potential improvement.
The workshop highlights the significance of graphical user interfaces (GUIs) in facilitating user interactions with machine learning models. By integrating PyQt, a powerful GUI development library for Python, participants create a user-friendly interface that enables users to interact with the models effortlessly. The GUI provides options to select different preprocessing techniques, visualize model outputs such as confusion matrices and decision boundaries, and gain insights into the models' classification capabilities. One of the primary advantages of the graphical user interface is its ability to offer users a seamless and intuitive experience in predicting and classifying pancreatic cancer based on urinary biomarkers. The GUI empowers users to make informed decisions by allowing them to compare the performance of different classifiers under various preprocessing techniques.
Throughout the workshop, a strong emphasis is placed on the significance of proper data preprocessing, hyperparameter tuning, and robust model evaluation. These crucial steps contribute to building accurate and reliable machine learning models for pancreatic cancer prediction. By the culmination of the workshop, participants have gained valuable hands-on experience in data exploration, machine learning model building, hyperparameter tuning, and GUI development, all geared towards addressing the specific challenge of pancreatic cancer classification and prediction.
In conclusion, the Applied Data Science Workshop on "Urinary Biomarkers-Based Pancreatic Cancer Classification and Prediction Using Machine Learning with Python GUI" embarks on a comprehensive and transformative journey, bringing together data exploration, preprocessing, machine learning model selection, hyperparameter tuning, model evaluation, and GUI development. The project's focus on pancreatic cancer prediction using urinary biomarkers aligns with the pressing need for early detection and treatment of this deadly disease. As participants delve into the intricacies of machine learning and medical research, they contribute to the broader scientific community's ongoing efforts to combat cancer and improve patient outcomes. Through the integration of data science methodologies and powerful visualization tools, the workshop exemplifies the potential of machine learning in revolutionizing medical diagnostics and healthcare practices.







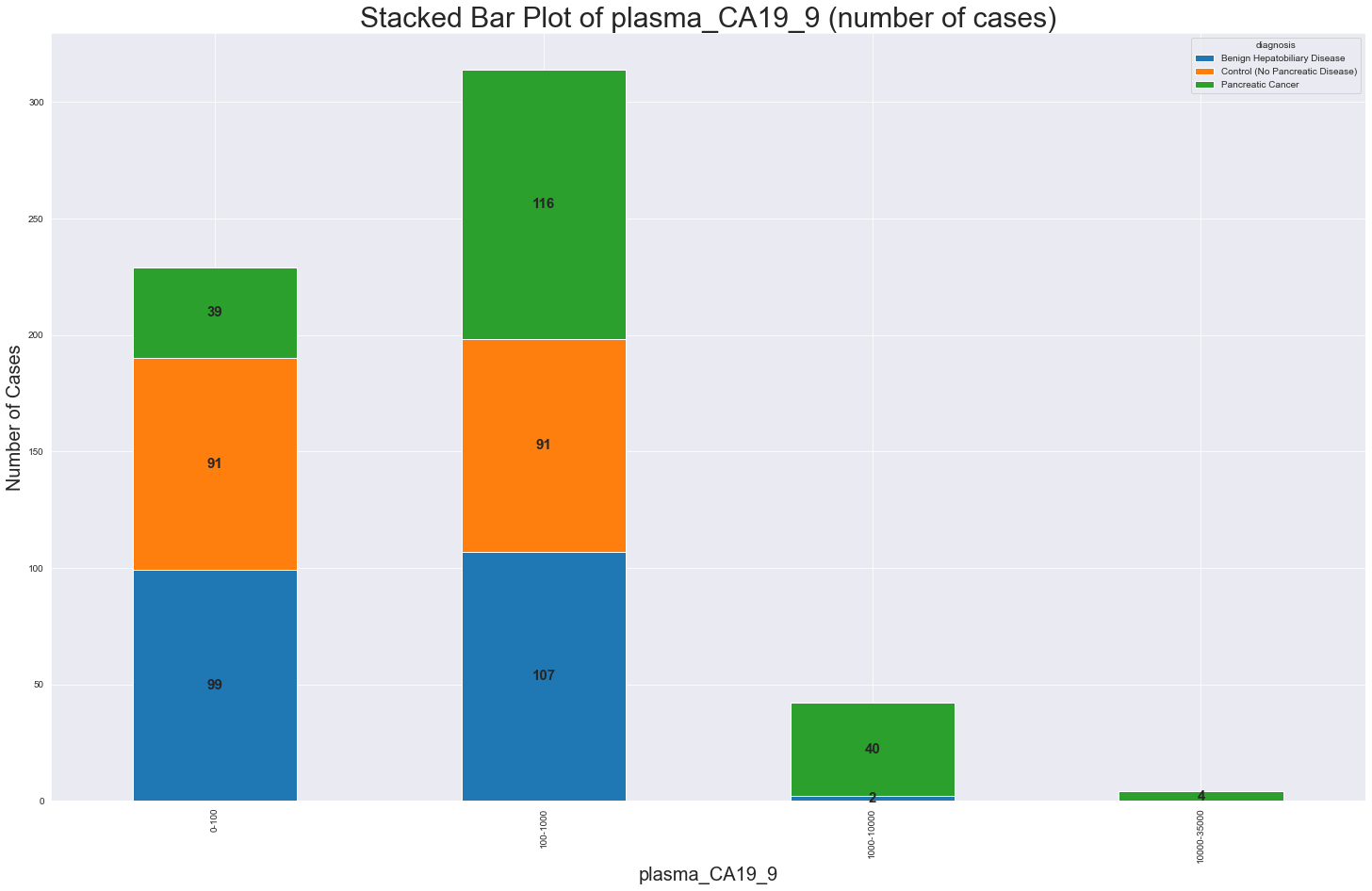















#pancreatic.py import numpy as np import pandas as pd import matplotlib import matplotlib.pyplot as plt import seaborn as sns sns.set_style('darkgrid') from sklearn.preprocessing import LabelEncoder import warnings warnings.filterwarnings('ignore') import os import plotly.graph_objs as go import joblib import itertools from sklearn.metrics import roc_auc_score,roc_curve from sklearn.model_selection import train_test_split, RandomizedSearchCV, GridSearchCV,StratifiedKFold from sklearn.preprocessing import StandardScaler, MinMaxScaler from sklearn.linear_model import LogisticRegression from sklearn.naive_bayes import GaussianNB from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier from xgboost import XGBClassifier from sklearn.neural_network import MLPClassifier from sklearn.linear_model import SGDClassifier from sklearn.preprocessing import StandardScaler, LabelEncoder, OneHotEncoder from sklearn.metrics import confusion_matrix, accuracy_score, recall_score, precision_score from sklearn.metrics import classification_report, f1_score, plot_confusion_matrix from catboost import CatBoostClassifier from lightgbm import LGBMClassifier from imblearn.over_sampling import SMOTE from sklearn.model_selection import learning_curve from mlxtend.plotting import plot_decision_regions #Reads dataset curr_path = os.getcwd() df = pd.read_csv(curr_path+"/Debernardi et al 2020 data.csv") print(df.iloc[:,0:8].head().to_string()) print(df.iloc[:,8:14].head().to_string()) #Checks shape print(df.shape) #Reads columns print("Data Columns --> ",df.columns) #Checks dataset information print(df.info()) #Drops irrelevant columns df = df.drop(columns=['sample_id','patient_cohort','sample_origin','stage','benign_sample_diagnosis']) #Checks null values print(df.isnull().sum()) print('Total number of null values: ', df.isnull().sum().sum()) #Imputes missing values in plasma_CA19_9 with mean df['plasma_CA19_9'].fillna((df['plasma_CA19_9'].mean()), inplace=True) #Imputes missing value in REG1A with mean df['REG1A'].fillna((df['REG1A'].mean()), inplace=True) #Checks null values print(df.isnull().sum()) print('Total number of null values: ', df.isnull().sum().sum()) #Looks at statistical description of data print(df.describe().iloc[:,0:5].to_string()) print(df.describe().iloc[:,5:10].to_string()) #Defines function to create pie chart and bar plot as subplots def plot_piechart(df, var, title=''): plt.figure(figsize=(25, 10)) plt.subplot(121) label_list = list(df[var].value_counts().index) colors = sns.color_palette("husl", len(label_list)) df[var].value_counts().plot.pie(autopct="%1.1f%%", \ colors=colors, \ startangle=60, labels=label_list, \ wedgeprops={"linewidth": 3, "edgecolor": "k"}, \ shadow=True, textprops={'fontsize': 20}) plt.title("Distribution of " + var + " variable " + title, fontsize=25) value_counts = df[var].value_counts() # Print percentage values percentages = value_counts / len(df) * 100 print("Percentage values:") print(percentages) plt.subplot(122) ax = df[var].value_counts().plot(kind="barh") for i, j in enumerate(df[var].value_counts().values): ax.text(.7, i, j, weight="bold", fontsize=20) plt.title("Count of " + var + " cases " + title, fontsize=25) # Print count values print("Count values:") print(value_counts) plt.show() plot_piechart(df,'diagnosis') # Looks at distribution of all features in the whole original dataset columns = list(df.columns) columns.remove('diagnosis') plt.subplots(figsize=(45, 50)) length = len(columns) color_palette = sns.color_palette("Set3", n_colors=length) # Define color palette for i, j in itertools.zip_longest(columns, range(length)): plt.subplot((length // 2), 4, j + 1) plt.subplots_adjust(wspace=0.2, hspace=0.5) ax = df[i].hist(bins=10, edgecolor='black', color=color_palette[j]) # Set color for each histogram for p in ax.patches: ax.annotate(format(p.get_height(), '.0f'), (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', xytext=(0, 10), weight="bold", fontsize=17, textcoords='offset points') plt.title(i, fontsize=30) # Adjust title font size plt.show() from tabulate import tabulate def another_versus_diagnosis(feat, num_bins): fig, axes = plt.subplots(nrows=3, ncols=1, figsize=(30, 22)) plt.subplots_adjust(wspace=0.5, hspace=0.25) colors = sns.color_palette("Set2") diagnosis_labels = {1: 'Control (No Pancreatic Disease)', 2: 'Benign Hepatobiliary Disease', 3: 'Pancreatic Cancer'} data = {} for diagnosis_code, ax in zip([1, 2, 3], axes): subset_data = df[df['diagnosis'] == diagnosis_code][feat] subset_data.plot(ax=ax, kind='hist', bins=num_bins, edgecolor='black', color=colors[diagnosis_code-1]) ax.set_title(diagnosis_labels[diagnosis_code], fontsize=30) ax.set_xlabel(feat, fontsize=30) ax.set_ylabel('Count', fontsize=30) patch_data = [] for p in ax.patches: x = p.get_x() + p.get_width() / 2. y = p.get_height() ax.annotate(format(y, '.0f'), (x, y), ha='center', va='center', xytext=(0, 10), weight="bold", fontsize=25, textcoords='offset points') patch_data.append([x, y]) data[diagnosis_labels[diagnosis_code]] = patch_data plt.show() for diagnosis_label, patch_data in data.items(): print(diagnosis_label + ":") print(tabulate(patch_data, headers=[feat, diagnosis_label])) print() #Looks at plasma_CA19_9 feature distribution by diagnosis feature another_versus_diagnosis("plasma_CA19_9", 10) #Looks at creatinine feature distribution by diagnosis feature another_versus_diagnosis("creatinine", 10) #Looks at LYVE1 feature distribution by diagnosis feature another_versus_diagnosis("LYVE1", 10) #Looks at REG1B feature distribution by diagnosis feature another_versus_diagnosis("REG1B", 10) #Looks at TFF1 feature distribution by diagnosis feature another_versus_diagnosis("TFF1", 10) #Looks at REG1A feature distribution by diagnosis feature another_versus_diagnosis("REG1A", 10) #Creates a dummy dataframe for visualization df_dummy=df.copy() #Categorizes diagnosis feature def cat_diagnosis(n): if n == 1: return 'Control (No Pancreatic Disease)' if n == 2: return 'Benign Hepatobiliary Disease' else: return 'Pancreatic Cancer' df_dummy['diagnosis'] = df_dummy['diagnosis'].apply(lambda x: cat_diagnosis(x)) def put_label_stacked_bar(ax,fontsize): #patches is everything inside of the chart for rect in ax.patches: # Find where everything is located height = rect.get_height() width = rect.get_width() x = rect.get_x() y = rect.get_y() # The height of the bar is the data value and can be used as the label label_text = f'{height:.0f}' # ax.text(x, y, text) label_x = x + width / 2 label_y = y + height / 2 # plots only when height is greater than specified value if height > 0: ax.text(label_x, label_y, label_text, \ ha='center', va='center', \ weight = "bold",fontsize=fontsize) #Plots one variable against another variable def dist_one_vs_another_plot(df, cat1, cat2): fig = plt.figure(figsize=(25, 15)) ax1 = fig.add_subplot(111) group_by_stat = df.groupby([cat1, cat2]).size() stacked_data = group_by_stat.unstack() group_by_stat.unstack().plot(kind='bar', stacked=True, ax=ax1, grid=True) ax1.set_title('Stacked Bar Plot of ' + cat1 + ' (number of cases)', fontsize=30) ax1.set_ylabel('Number of Cases', fontsize=20) ax1.set_xlabel(cat1, fontsize=20) put_label_stacked_bar(ax1,15) plt.show() # Group values by cat2 sentiment_groups = stacked_data.groupby(level=0, axis=0) # Create table headers headers = [cat2 for cat2 in stacked_data.columns] # Create table rows with data rows = [] for cat, group_data in sentiment_groups: row_values = [str(val) for val in group_data.values.flatten()] rows.append([cat] + row_values) # Print the table print(tabulate(rows, headers=headers, tablefmt='grid')) #Categorizes age feature labels = ['0-40', '40-50', '50-60','60-90'] df_dummy['age'] = pd.cut(df_dummy['age'], [0, 40, 50, 60, 90], labels=labels) #Plots the distribution of age feature in pie chart and bar plot plot_piechart(df_dummy,'age',) #Plots diagnosis variable against age variable in stacked bar plots dist_one_vs_another_plot(df_dummy,'age', 'diagnosis') #Plots the distribution of sex feature in pie chart and bar plot plot_piechart(df_dummy,'sex') #Plots diagnosis variable against sex variable in stacked bar plots dist_one_vs_another_plot(df_dummy,'sex', 'diagnosis') #Categorizes plasma_CA19_9 feature labels = ['0-100', '100-1000', '1000-10000','10000-35000'] df_dummy['plasma_CA19_9'] = pd.cut(df_dummy['plasma_CA19_9'], [0, 100, 1000, 10000, 35000], labels=labels) #Plots the distribution of plasma_CA19_9 feature in pie chart and bar plot plot_piechart(df_dummy,'plasma_CA19_9') #Plots diagnosis variable against plasma_CA19_9 variable in stacked bar plots dist_one_vs_another_plot(df_dummy,'plasma_CA19_9', 'diagnosis') #Categorizes creatinine feature labels = ['0-0.5', '0.5-1', '1-2','2-5'] df_dummy['creatinine'] = pd.cut(df_dummy['creatinine'], [0, 0.5, 1, 2, 5], labels=labels) #Plots the distribution of creatinine feature in pie chart and bar plot plot_piechart(df_dummy,'creatinine') #Plots diagnosis variable against creatinine variable in stacked bar plots dist_one_vs_another_plot(df_dummy,'creatinine', 'diagnosis') #Checks dataset information print(df_dummy.info()) #Extracts categorical and numerical columns cat_cols = [col for col in df_dummy.columns if (df_dummy[col].dtype == 'object' or df_dummy[col].dtype.name == 'category')] num_cols = [col for col in df_dummy.columns if (df_dummy[col].dtype != 'object' and df_dummy[col].dtype.name != 'category')] print(cat_cols) print(num_cols) #Checks numerical features density distribution # Define a custom color palette colors = sns.color_palette("husl", len(num_cols)) # Checks numerical features density distribution fig = plt.figure(figsize=(30, 20)) plotnumber = 1 for i, column in enumerate(num_cols): if plotnumber <= 6: ax = plt.subplot(2, 2, plotnumber) sns.distplot(df_dummy[column], color=colors[i]) # Use the custom color for the plot plt.xlabel(column, fontsize=40) for p in ax.patches: ax.annotate(format(p.get_height(), '.2f'), (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', xytext=(0, 10), weight="bold", fontsize=30, textcoords='offset points') plotnumber += 1 fig.suptitle('The density of numerical features', fontsize=50) plt.tight_layout() plt.show() #Checks categorical features distribution fig=plt.figure(figsize = (35, 25)) plotnumber = 1 for column in cat_cols: if plotnumber <= 6: ax = plt.subplot(2, 3, plotnumber) sns.countplot(df_dummy[column], palette = 'Spectral_r') plt.xlabel(column,fontsize=40) for p in ax.patches: ax.annotate(format(p.get_height(), '.0f'), (p.get_x() + p.get_width() / 2., p.get_height()), ha = 'center', va = 'center', xytext = (0, 10), weight = "bold",fontsize=30, textcoords = 'offset points') plotnumber += 1 fig.suptitle('The distribution of categorical features distribution', fontsize=50) plt.tight_layout() plt.show() def plot_four_versus_one(df, column_names, feat): num_plots = len(column_names) num_rows = num_plots // 2 + num_plots % 2 fig, ax = plt.subplots(num_rows, 2, figsize=(20, 13), facecolor='#fbe7dd') for i, column in enumerate(column_names): current_ax = ax[i // 2, i % 2] g = sns.countplot(df[column], hue=df[feat], palette='Spectral_r', ax=current_ax) for p in g.patches: g.annotate(format(p.get_height(), '.0f'), (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', xytext=(0, 10), weight="bold", fontsize=20, textcoords='offset points') current_ax.set_xlabel(column, fontsize=20) current_ax.set_ylabel("Count", fontsize=20) current_ax.tick_params(axis='x', labelsize=15) current_ax.tick_params(axis='y', labelsize=15) plt.tight_layout() plt.show() #Plots distribution of number of cases of four categorical features versus diagnosis column_names = ["age", "sex", "plasma_CA19_9", "creatinine"] plot_four_versus_one(df_dummy, column_names, "diagnosis") #Plots distribution of number of cases of four categorical features versus creatinine column_names = ["age", "sex", "plasma_CA19_9", "diagnosis"] plot_four_versus_one(df_dummy, column_names, "creatinine") #Plots distribution of number of cases of four categorical features versus age column_names = ["creatinine", "sex", "plasma_CA19_9", "diagnosis"] plot_four_versus_one(df_dummy, column_names, "age") #Plots distribution of number of cases of four categorical features versus sex column_names = ["creatinine", "age", "plasma_CA19_9", "diagnosis"] plot_four_versus_one(df_dummy, column_names, "sex") #Plots distribution of number of cases of four categorical features versus plasma_CA19_9 column_names = ["creatinine", "age", "sex", "diagnosis"] plot_four_versus_one(df_dummy, column_names, "plasma_CA19_9") #Categorizes diagnosis feature def cat_diagnosis(n): if n == 1: return 'Control (No Pancreatic Disease)' if n == 2: return 'Benign Hepatobiliary Disease' else: return 'Pancreatic Cancer' #Plots distribution of age and sex versus diagnosis in pie chart def plot_piechart_diagnosis(df, feat1, feat2): gs0 = df_dummy[df_dummy.diagnosis == 'Control (No Pancreatic Disease)'][feat1].value_counts() gs1 = df_dummy[df_dummy.diagnosis == 'Benign Hepatobiliary Disease'][feat1].value_counts() gs2 = df_dummy[df_dummy.diagnosis == 'Pancreatic Cancer'][feat1].value_counts() ss0 = df_dummy[df_dummy.diagnosis == 'Control (No Pancreatic Disease)'][feat2].value_counts() ss1 = df_dummy[df_dummy.diagnosis == 'Benign Hepatobiliary Disease'][feat2].value_counts() ss2 = df_dummy[df_dummy.diagnosis == 'Pancreatic Cancer'][feat2].value_counts() label_gs0=list(gs0.index) label_gs1=list(gs1.index) label_gs2=list(gs2.index) label_ss0=list(ss0.index) label_ss1=list(ss1.index) label_ss2=list(ss2.index) fig, ax = plt.subplots(2, 3, figsize=(35, 20), facecolor='#fbe7dd') def print_percentage_table(data, labels, title): percentages = [f'{(value / sum(data)) * 100:.1f}%' for value in data] table_data = list(zip(labels, percentages)) headers = [feat1, 'Percentage'] print(f"\n{title}:") print(tabulate(table_data, headers=headers, tablefmt='grid')) def plot_pie(ax, data, labels, title): ax.pie(data, labels=labels, shadow=True, autopct='%1.1f%%', textprops={'fontsize': 32}) ax.set_xlabel(title, fontsize=30) plot_pie(ax[0, 0], gs0, label_gs0, f"{feat1} feature") print_percentage_table(gs0, label_gs0, 'diagnosis = Control (No Pancreatic Disease)') plot_pie(ax[0, 1], gs1, label_gs1, f"{feat1} feature") print_percentage_table(gs1, label_gs1, 'diagnosis = Benign Hepatobiliary Disease') plot_pie(ax[0, 2], gs1, label_gs1, f"{feat1} feature") print_percentage_table(gs1, label_gs2, 'diagnosis = Pancreatic Cancer') plot_pie(ax[1, 0], ss0, label_ss0, f"{feat2} feature") print_percentage_table(ss0, label_ss0, 'diagnosis = Control (No Pancreatic Disease)') plot_pie(ax[1, 1], ss1, label_ss1, f"{feat2} feature") print_percentage_table(ss1, label_ss1, 'diagnosis = Benign Hepatobiliary Disease') plot_pie(ax[1, 2], ss1, label_ss1, f"{feat2} feature") print_percentage_table(ss1, label_ss2, 'diagnosis = Pancreatic Cancer') ax[0][0].set_title('diagnosis = Control (No Pancreatic Disease)',fontsize= 30) ax[0][1].set_title('diagnosis = Benign Hepatobiliary Disease',fontsize= 30) ax[0][2].set_title('diagnosis = Pancreatic Cancer',fontsize= 30) plt.tight_layout() plt.show() #Plots distribution of age and sex versus diagnosis in pie chart plot_piechart_diagnosis(df_dummy, "age", "sex") #Plots distribution of plasma_CA19_9 and creatinine versus diagnosis in pie chart plot_piechart_diagnosis(df_dummy, "plasma_CA19_9", "sex") plt.rcParams['figure.dpi'] = 600 fig = plt.figure(figsize=(10,5)) gs = fig.add_gridspec(2, 2) gs.update(wspace=0.15, hspace=0.25) background_color = "#fbe7dd" sns.set_palette(['#ff355d','#ffd514']) def feat_versus_other(feat,another,legend,ax0,label): for s in ["right", "top"]: ax0.spines[s].set_visible(False) ax0.set_facecolor(background_color) ax0_sns = sns.histplot(data=df, x=feat,ax=ax0,zorder=2,kde=False,hue=another,multiple="stack", shrink=.8 ,linewidth=0.3,alpha=1) put_label_stacked_bar(ax0_sns,5) ax0_sns.set_xlabel('',fontsize=4, weight='bold') ax0_sns.set_ylabel('',fontsize=4, weight='bold') ax0_sns.grid(which='major', axis='x', zorder=0, color='#EEEEEE', linewidth=0.4) ax0_sns.grid(which='major', axis='y', zorder=0, color='#EEEEEE', linewidth=0.4) ax0_sns.tick_params(labelsize=3, width=0.5, length=1.5) ax0_sns.legend(legend, ncol=2, facecolor='#D8D8D8', edgecolor=background_color, fontsize=3, bbox_to_anchor=(1, 0.989), loc='upper right') ax0.set_facecolor(background_color) ax0_sns.set_xlabel(label) plt.tight_layout() def prob_feat_versus_other(feat,another,legend,ax0,label): for s in ["right", "top"]: ax0.spines[s].set_visible(False) ax0.set_facecolor(background_color) ax0_sns = sns.kdeplot(x=feat,ax=ax0,hue=another,linewidth=0.3,fill=True,cbar='g',zorder=2,alpha=1,multiple='stack') ax0_sns.set_xlabel('',fontsize=4, weight='bold') ax0_sns.set_ylabel('',fontsize=4, weight='bold') ax0_sns.grid(which='major', axis='x', zorder=0, color='#EEEEEE', linewidth=0.4) ax0_sns.grid(which='major', axis='y', zorder=0, color='#EEEEEE', linewidth=0.4) ax0_sns.tick_params(labelsize=3, width=0.5, length=1.5) ax0_sns.legend(legend, ncol=2, facecolor='#D8D8D8', edgecolor=background_color, fontsize=3, bbox_to_anchor=(1, 0.989), loc='upper right') ax0.set_facecolor(background_color) ax0_sns.set_xlabel(label) plt.tight_layout() label_diag = list(df_dummy["diagnosis"].value_counts().index) label_age = list(df_dummy["age"].value_counts().index) label_plas = list(df_dummy["plasma_CA19_9"].value_counts().index) label_sex = list(df_dummy["sex"].value_counts().index) def hist_feat_versus_four_cat(feat,label): ax0 = fig.add_subplot(gs[0, 0]) feat_versus_other(feat,df_dummy["diagnosis"],label_diag,ax0,"diagnosis versus " + label) ax1 = fig.add_subplot(gs[0, 1]) feat_versus_other(feat,df_dummy["age"],label_age,ax1,"age versus " + label) ax2 = fig.add_subplot(gs[1, 0]) feat_versus_other(feat,df_dummy["plasma_CA19_9"],label_plas,ax2,"plasma_CA19_9 versus " + label) ax3 = fig.add_subplot(gs[1, 1]) feat_versus_other(feat,df_dummy["creatinine"],label_sex,ax3,"sex versus " + label) def prob_feat_versus_four_cat(feat,label): ax0 = fig.add_subplot(gs[0, 0]) prob_feat_versus_other(feat,df_dummy["diagnosis"],label_diag,ax0,"diagnosis versus " + label) ax1 = fig.add_subplot(gs[0, 1]) prob_feat_versus_other(feat,df_dummy["age"],label_age,ax1,"age versus " + label) ax2 = fig.add_subplot(gs[1, 0]) prob_feat_versus_other(feat,df_dummy["plasma_CA19_9"],label_plas,ax2,"plasma_CA19_9 versus " + label) ax3 = fig.add_subplot(gs[1, 1]) prob_feat_versus_other(feat,df_dummy["creatinine"],label_sex,ax3,"sex versus " + label) #hist_feat_versus_four_cat(df_dummy["LYVE1"],"LYVE1") prob_feat_versus_four_cat(df_dummy["LYVE1"],"LYVE1") hist_feat_versus_four_cat(df_dummy["REG1B"],"REG1B") prob_feat_versus_four_cat(df_dummy["REG1B"],"REG1B") hist_feat_versus_four_cat(df_dummy["TFF1"],"TFF1") prob_feat_versus_four_cat(df_dummy["TFF1"],"TFF1") #hist_feat_versus_four_cat(df_dummy["REG1A"],"REG1A") prob_feat_versus_four_cat(df_dummy["REG1A"],"REG1A") #Converts sex feature to {0,1} def map_sex(n): if n == "F": return 0 else: return 1 df['sex'] = df['sex'].apply(lambda x: map_sex(x)) #Converts diagnosis feature to {0,1,2} def map_diagnosis(n): if n == 1: return 0 if n == 2: return 1 else: return 2 df['diagnosis'] = df['diagnosis'].apply(lambda x: map_diagnosis(x)) #Extracts outuput and input variables y = df['diagnosis'].values # Target for the model X = df.drop(['diagnosis'], axis = 1) #Feature Importance using RandomForest Classifier names = X.columns rf = RandomForestClassifier() rf.fit(X, y) result_rf = pd.DataFrame() result_rf['Features'] = X.columns result_rf ['Values'] = rf.feature_importances_ result_rf.sort_values('Values', inplace = True, ascending = False) plt.figure(figsize=(25,25)) sns.set_color_codes("pastel") sns.barplot(x = 'Values',y = 'Features', data=result_rf, color="Blue") plt.xlabel('Feature Importance', fontsize=30) plt.ylabel('Feature Labels', fontsize=30) plt.tick_params(axis='x', labelsize=20) plt.tick_params(axis='y', labelsize=20) plt.show() # Print the feature importance table print("Feature Importance:") print(result_rf) #Feature Importance using ExtraTreesClassifier model = ExtraTreesClassifier() model.fit(X, y) result_et = pd.DataFrame() result_et['Features'] = X.columns result_et ['Values'] = model.feature_importances_ result_et.sort_values('Values', inplace=True, ascending =False) plt.figure(figsize=(25,25)) sns.set_color_codes("pastel") sns.barplot(x = 'Values',y = 'Features', data=result_et, color="red") plt.xlabel('Feature Importance', fontsize=30) plt.ylabel('Feature Labels', fontsize=30) plt.tick_params(axis='x', labelsize=20) plt.tick_params(axis='y', labelsize=20) plt.show() # Print the feature importance table print("Feature Importance:") print(result_et) #Feature Importance using RFE from sklearn.feature_selection import RFE model = LogisticRegression() # create the RFE model rfe = RFE(model) rfe = rfe.fit(X, y) result_lg = pd.DataFrame() result_lg['Features'] = X.columns result_lg ['Ranking'] = rfe.ranking_ result_lg.sort_values('Ranking', inplace=True , ascending = False) plt.figure(figsize=(25,25)) sns.set_color_codes("pastel") sns.barplot(x = 'Ranking',y = 'Features', data=result_lg, color="orange") plt.ylabel('Feature Labels', fontsize=30) plt.tick_params(axis='x', labelsize=20) plt.tick_params(axis='y', labelsize=20) plt.show() print("Feature Ranking:") print(result_lg) #Splits the data into training and testing sm = SMOTE(random_state=42) X,y = sm.fit_resample(X, y.ravel()) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 2021, stratify=y) X_train_raw = X_train.copy() X_test_raw = X_test.copy() y_train_raw = y_train.copy() y_test_raw = y_test.copy() X_train_norm = X_train.copy() X_test_norm = X_test.copy() y_train_norm = y_train.copy() y_test_norm = y_test.copy() norm = MinMaxScaler() X_train_norm = norm.fit_transform(X_train_norm) X_test_norm = norm.transform(X_test_norm) X_train_stand = X_train.copy() X_test_stand = X_test.copy() y_train_stand = y_train.copy() y_test_stand = y_test.copy() scaler = StandardScaler() X_train_stand = scaler.fit_transform(X_train_stand) X_test_stand = scaler.transform(X_test_stand) def plot_learning_curve(estimator, title, X, y, axes=None, ylim=None, cv=None, n_jobs=None, train_sizes=np.linspace(.1, 1.0, 5)): if axes is None: _, axes = plt.subplots(3, 1, figsize=(50, 50)) axes[0].set_title(title) if ylim is not None: axes[0].set_ylim(*ylim) axes[0].set_xlabel("Training examples") axes[0].set_ylabel("Score") train_sizes, train_scores, test_scores, fit_times, _ = \ learning_curve(estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, return_times=True) train_scores_mean = np.mean(train_scores, axis=1) train_scores_std = np.std(train_scores, axis=1) test_scores_mean = np.mean(test_scores, axis=1) test_scores_std = np.std(test_scores, axis=1) fit_times_mean = np.mean(fit_times, axis=1) fit_times_std = np.std(fit_times, axis=1) # Plot learning curve axes[0].grid() axes[0].fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color="r") axes[0].fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color="g") axes[0].plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score", lw=10) axes[0].plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score", lw=10) axes[0].legend(loc="best") axes[0].set_title('Learning Curve', fontsize=50) axes[0].set_xlabel('Training Examples', fontsize=40) axes[0].set_ylabel('Score', fontsize=40) axes[0].tick_params(labelsize=30) # Plot n_samples vs fit_times axes[1].grid() axes[1].plot(train_sizes, fit_times_mean, 'o-', lw=10) axes[1].fill_between(train_sizes, fit_times_mean - fit_times_std, fit_times_mean + fit_times_std, alpha=0.1) axes[1].set_xlabel("Training examples", fontsize=40) axes[1].set_ylabel("fit_times", fontsize=40) axes[1].set_title("Scalability of the model", fontsize=50) axes[1].tick_params(labelsize=30) # Plot fit_time vs score axes[2].grid() axes[2].plot(fit_times_mean, test_scores_mean, 'o-', lw=10) axes[2].fill_between(fit_times_mean, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1) axes[2].set_xlabel("fit_times", fontsize=40) axes[2].set_ylabel("Score", fontsize=40) axes[2].set_title("Performance of the model", fontsize=50) return plt def plot_real_pred_val(Y_test, ypred, name): plt.figure(figsize=(20,12)) acc=accuracy_score(Y_test,ypred) plt.scatter(range(len(ypred)),ypred,color="blue",lw=5,label="Predicted") plt.scatter(range(len(Y_test)), Y_test,color="red",label="Actual") plt.title("Predicted Values vs True Values of " + name, fontsize=30) plt.xlabel("Accuracy: " + str(round((acc*100),3)) + "%", fontsize=30) plt.legend() plt.grid(True, alpha=0.75, lw=1, ls='-.') plt.show() def plot_cm(Y_test, ypred, name): fig, ax = plt.subplots(figsize=(25, 15)) cm = confusion_matrix(Y_test, ypred) sns.heatmap(cm, annot=True, linewidth=0.7, linecolor='red', fmt='g', cmap="YlOrBr", annot_kws={"size": 30}) plt.title(name + ' Confusion Matrix', fontsize=30) ax.xaxis.set_ticklabels(['Control (No Pancreatic Disease)', 'Benign Hepatobiliary Disease', 'Pancreatic Cancer'], fontsize=20); ax.yaxis.set_ticklabels(['Control (No Pancreatic Disease)', 'Benign Hepatobiliary Disease', 'Pancreatic Cancer'], fontsize=20); plt.xlabel('Y predict', fontsize=30) plt.ylabel('Y test', fontsize=30) plt.show() return cm #Plots ROC def plot_roc(model,X_test, y_test, title): Y_pred_prob = model.predict_proba(X_test) Y_pred_prob = Y_pred_prob[:, 1] fpr, tpr, thresholds = roc_curve(y_test, Y_pred_prob) plt.figure(figsize=(25,15)) plt.plot([0,1],[0,1], color='navy', lw=10, linestyle='--') plt.plot(fpr,tpr, color='red', lw=10) plt.xlabel('False Positive Rate', fontsize=30) plt.ylabel('True Positive Rate', fontsize=30) plt.title('ROC Curve of ' + title, fontsize=30) plt.grid(True) plt.show() def plot_decision_boundary(model,xtest, ytest, name): plt.figure(figsize=(25, 15)) #Trains model with two features model.fit(xtest, ytest) plot_decision_regions(xtest.values, ytest.ravel(), \ clf=model, legend=2) plt.title("Decision boundary for " + name + " (Test)", fontsize=30) plt.xlabel("creatinine", fontsize=25) plt.ylabel("LYVE1", fontsize=25) plt.legend(fontsize=25) plt.show() #Chooses two features for decision boundary feat_boundary = ['creatinine','LYVE1'] X_feature = X[feat_boundary] X_train_feat, X_test_feat, y_train_feat, y_test_feat = train_test_split(X_feature, y, test_size = 0.2, random_state = 2021, stratify=y) def train_model(model, X, y): model.fit(X, y) return model def predict_model(model, X, proba=False): if ~proba: y_pred = model.predict(X) else: y_pred_proba = model.predict_proba(X) y_pred = np.argmax(y_pred_proba, axis=1) return y_pred list_scores = [] def run_model(name, model, X_train, X_test, y_train, y_test, fc, proba=False): print(name) print(fc) model = train_model(model, X_train, y_train) y_pred = predict_model(model, X_test, proba) accuracy = accuracy_score(y_test, y_pred) recall = recall_score(y_test, y_pred, average='weighted') precision = precision_score(y_test, y_pred, average='weighted') f1 = f1_score(y_test, y_pred, average='weighted') print('accuracy: ', accuracy) print('recall: ',recall) print('precision: ', precision) print('f1: ', f1) print(classification_report(y_test, y_pred)) plot_cm(y_test, y_pred, name) plot_real_pred_val(y_test, y_pred, name) plot_decision_boundary(model,X_test_feat, y_test_feat, name) plot_learning_curve(model, name, X_train, y_train, cv=3); plt.show() list_scores.append({'Model Name': name, 'Feature Scaling':fc, 'Accuracy': accuracy, 'Recall': recall, 'Precision': precision, 'F1':f1}) feature_scaling = { #'Raw':(X_train_raw, X_test_raw, y_train_raw, y_test_raw), #'Normalization':(X_train_norm, X_test_norm, y_train_norm, y_test_norm), 'Standardization':(X_train_stand, X_test_stand, y_train_stand, y_test_stand), } #Support Vector Classifier # Define the parameter grid for the Grid Search param_grid = { 'C': [0.1, 1, 10], # Regularization parameter 'kernel': ['linear', 'rbf'], # Kernel type } # Create the SVC model with probability=True model_svc = SVC(random_state=2021, probability=True) # Perform Grid Search for each feature scaling method for fc_name, value in feature_scaling.items(): X_train, X_test, y_train, y_test = value # Initialize GridSearchCV grid_search = GridSearchCV(estimator=model_svc, param_grid=param_grid, cv=3, scoring='accuracy', n_jobs=-1) # Perform Grid Search and fit the model grid_search.fit(X_train, y_train) # Get the best parameters and best model from the Grid Search best_params = grid_search.best_params_ best_model = grid_search.best_estimator_ # Evaluate the best model run_model('SVC with ' + fc_name, best_model, X_train, X_test, y_train, y_test, fc_name, proba=True) # Print the best hyperparameters found print(f"Best Hyperparameters for {fc_name}:") print(grid_search.best_params_) #Logistic Regression Classifier # Define the parameter grid for the grid search param_grid = { 'C': [0.01, 0.1, 1, 10], 'penalty': ['l1', 'l2'], 'solver': ['newton-cg', 'lbfgs', 'liblinear', 'saga'], } # Initialize the Logistic Regression model logreg = LogisticRegression(max_iter=5000, random_state=2021) # Perform the grid search for each feature scaling method for fc_name, value in feature_scaling.items(): X_train, X_test, y_train, y_test = value # Create GridSearchCV with the Logistic Regression model and the parameter grid grid_search = GridSearchCV(logreg, param_grid, cv=3, scoring='accuracy', n_jobs=-1) # Train and perform grid search grid_search.fit(X_train, y_train) # Get the best Logistic Regression model from the grid search best_model = grid_search.best_estimator_ # Evaluate and plot the best model (setting proba=True for probability prediction) run_model('Logistic Regression', best_model, X_train, X_test, y_train, y_test, fc_name, proba=True) # Print the best hyperparameters found print(f"Best Hyperparameters for {fc_name}:") print(grid_search.best_params_) #KNN Classifier # Define the parameter grid for the grid search param_grid = { 'n_neighbors': list(range(2, 10)) } # KNN Classifier Grid Search for fc_name, value in feature_scaling.items(): X_train, X_test, y_train, y_test = value # Initialize the KNN Classifier knn = KNeighborsClassifier() # Create GridSearchCV with the KNN model and the parameter grid grid_search = GridSearchCV(knn, param_grid, cv=3, scoring='accuracy', n_jobs=-1) # Train and perform grid search grid_search.fit(X_train, y_train) # Get the best KNN model from the grid search best_model = grid_search.best_estimator_ # Evaluate and plot the best model (setting proba=True for probability prediction) run_model(f'KNeighbors Classifier n_neighbors = {grid_search.best_params_["n_neighbors"]}', best_model, X_train, X_test, y_train, y_test, fc_name, proba=True) # Print the best hyperparameters found print(f"Best Hyperparameters for {fc_name}:") print(grid_search.best_params_) #Decision Tree Classifier for fc_name, value in feature_scaling.items(): X_train, X_test, y_train, y_test = value # Initialize the DecisionTreeClassifier model dt_clf = DecisionTreeClassifier(random_state=2021) # Define the parameter grid for the grid search param_grid = { 'max_depth': np.arange(1, 51, 1), 'criterion': ['gini', 'entropy'], 'min_samples_split': [2, 5, 10], 'min_samples_leaf': [1, 2, 4], } # Create GridSearchCV with the DecisionTreeClassifier model and the parameter grid grid_search = GridSearchCV(dt_clf, param_grid, cv=3, scoring='accuracy', n_jobs=-1) # Train and perform grid search grid_search.fit(X_train, y_train) # Get the best DecisionTreeClassifier model from the grid search best_model = grid_search.best_estimator_ # Evaluate and plot the best model (setting proba=True for probability prediction) run_model(f'DecisionTree Classifier (Best Depth: {grid_search.best_params_["max_depth"]})', best_model, X_train, X_test, y_train, y_test, fc_name, proba=True) # Print the best hyperparameters found print(f"Best Hyperparameters for {fc_name}:") print(grid_search.best_params_) #Random Forest Classifier # Define the parameter grid for the grid search param_grid = { 'n_estimators': [100, 200, 300], 'max_depth': [10, 20, 30, 40, 50], 'min_samples_split': [2, 5, 10], 'min_samples_leaf': [1, 2, 4] } # Initialize the RandomForestClassifier model rf = RandomForestClassifier(random_state=2021) # RandomForestClassifier Grid Search for fc_name, value in feature_scaling.items(): X_train, X_test, y_train, y_test = value # Create GridSearchCV with the RandomForestClassifier model and the parameter grid grid_search = GridSearchCV(rf, param_grid, cv=3, scoring='accuracy', n_jobs=-1) # Train and perform grid search grid_search.fit(X_train, y_train) # Get the best RandomForestClassifier model from the grid search best_model = grid_search.best_estimator_ # Evaluate and plot the best model (setting proba=True for probability prediction) run_model(f'RandomForest Classifier (Best Estimators: {grid_search.best_params_["n_estimators"]})', best_model, X_train, X_test, y_train, y_test, fc_name, proba=True) # Print the best hyperparameters found print(f"Best Hyperparameters for {fc_name}:") print(grid_search.best_params_) #Gradient Boosting Classifier # Initialize the GradientBoostingClassifier model gbt = GradientBoostingClassifier(random_state=2021) # Define the parameter grid for the grid search param_grid = { 'n_estimators': [100, 200, 300], 'max_depth': [10, 20, 30], 'subsample': [0.6, 0.8, 1.0], 'max_features': [0.2, 0.4, 0.6, 0.8, 1.0], } # GradientBoosting Classifier Grid Search for fc_name, value in feature_scaling.items(): X_train, X_test, y_train, y_test = value # Create GridSearchCV with the GradientBoostingClassifier model and the parameter grid grid_search = GridSearchCV(gbt, param_grid, cv=3, scoring='accuracy', n_jobs=-1) # Train and perform grid search grid_search.fit(X_train, y_train) # Get the best GradientBoostingClassifier model from the grid search best_model = grid_search.best_estimator_ # Evaluate and plot the best model (setting proba=True for probability prediction) run_model(f'GradientBoosting Classifier (Best Estimators: {grid_search.best_params_["n_estimators"]})', best_model, X_train, X_test, y_train, y_test, fc_name, proba=True) # Print the best hyperparameters found print(f"Best Hyperparameters for {fc_name}:") print(grid_search.best_params_) #Extreme Gradient Boosting Classifier # XGBoost Classifier Grid Search for fc_name, value in feature_scaling.items(): X_train, X_test, y_train, y_test = value # Define the parameter grid for the grid search param_grid = { 'n_estimators': [100, 200, 300], 'max_depth': [10, 20, 30], 'learning_rate': [0.01, 0.1, 0.2], 'subsample': [0.6, 0.8, 1.0], 'colsample_bytree': [0.6, 0.8, 1.0], } # Initialize the XGBoost classifier xgb = XGBClassifier(random_state=2021, use_label_encoder=False, eval_metric='mlogloss') # Create GridSearchCV with the XGBoost classifier and the parameter grid grid_search = GridSearchCV(xgb, param_grid, cv=3, scoring='accuracy', n_jobs=-1) # Train and perform grid search grid_search.fit(X_train, y_train) # Get the best XGBoost classifier model from the grid search best_model = grid_search.best_estimator_ # Evaluate and plot the best model (setting proba=True for probability prediction) run_model(f'XGB Classifier (Best Estimators: {grid_search.best_params_["n_estimators"]})', best_model, X_train, X_test, y_train, y_test, fc_name, proba=True) # Print the best hyperparameters found print(f"Best Hyperparameters for {fc_name}:") print(grid_search.best_params_) # MLP Classifier Grid Search for fc_name, value in feature_scaling.items(): X_train, X_test, y_train, y_test = value # Define the parameter grid for the grid search param_grid = { 'hidden_layer_sizes': [(50,), (100,), (50, 50), (100, 50), (100, 100)], 'activation': ['logistic', 'relu'], 'solver': ['adam', 'sgd'], 'alpha': [0.0001, 0.001, 0.01], 'learning_rate': ['constant', 'invscaling', 'adaptive'], } # Initialize the MLP Classifier mlp = MLPClassifier(random_state=2021) # Create GridSearchCV with the MLP Classifier and the parameter grid grid_search = GridSearchCV(mlp, param_grid, cv=3, scoring='accuracy', n_jobs=-1) # Train and perform grid search grid_search.fit(X_train, y_train) # Get the best MLP Classifier model from the grid search best_model = grid_search.best_estimator_ # Evaluate and plot the best model (setting proba=True for probability prediction) run_model('MLP Classifier', best_model, X_train, X_test, y_train, y_test, fc_name, proba=True) # Print the best hyperparameters found print(f"Best Hyperparameters for {fc_name}:") print(grid_search.best_params_) #LGBM Classifier # Define the parameter grid for grid search param_grid = { 'max_depth': [10, 20, 30], 'n_estimators': [100, 200, 300], 'subsample': [0.6, 0.8, 1.0], 'random_state': [2021] } # Initialize the LightGBM classifier lgbm = LGBMClassifier() # Grid Search for fc_name, value in feature_scaling.items(): X_train, X_test, y_train, y_test = value # Create GridSearchCV with the LightGBM classifier and the parameter grid grid_search = GridSearchCV(lgbm, param_grid, cv=3, scoring='accuracy', n_jobs=-1) # Train and perform grid search grid_search.fit(X_train, y_train) # Get the best LightGBM classifier model from the grid search best_model = grid_search.best_estimator_ # Evaluate and plot the best model (setting proba=True for probability prediction) run_model('LGBM Classifier', best_model, X_train, X_test, y_train, y_test, fc_name, proba=True) # Print the best hyperparameters found print(f"Best Hyperparameters for {fc_name}:") print(grid_search.best_params_)
No comments:
Post a Comment