
In this project, we aim to predict the risk of defaulting on a loan based on customer behavior using machine learning and deep learning techniques. We start by exploring the dataset and understanding its structure and contents.
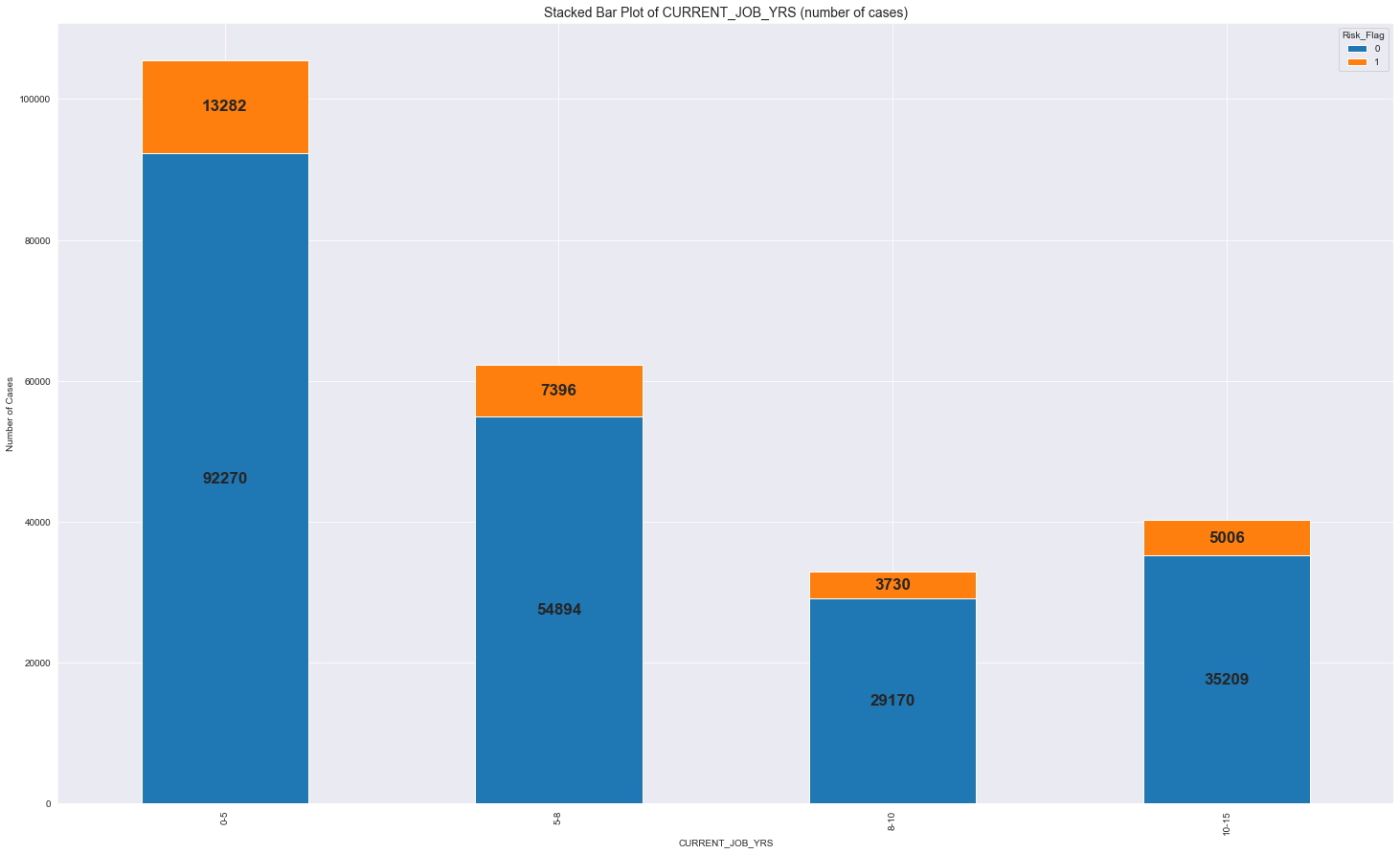
The dataset contains various features related to customer behavior, such as credit history, income, employment status, loan amount, and more. We analyze the distribution of these features to gain insights into their characteristics and potential impact on loan default. Next, we preprocess the data by handling missing values, encoding categorical variables, and normalizing numerical features. This ensures that the data is in a suitable format for training machine learning models.
To predict the risk flag for loan default, we apply various machine learning models. We start with logistic regression, which models the relationship between the input features and the probability of loan default. We evaluate the model's performance using metrics such as accuracy, precision, recall, and F1-score.
Next, we employ decision tree-based algorithms, such as random forest and gradient boosting, which can capture non-linear relationships and interactions among features. These models provide better predictive power and help identify important features that contribute to loan default. Additionally, we explore support vector machines (SVM), which aim to find an optimal hyperplane that separates the loan default and non-default instances in a high-dimensional feature space. SVMs can handle complex data distributions and can be tuned to optimize the classification performance.
After evaluating the performance of these machine learning models, we turn our attention to deep learning techniques. We design and train an Artificial Neural Network (ANN) to predict the risk flag for loan default. The ANN consists of multiple layers of interconnected neurons that learn hierarchical representations of the input features.
We configure the ANN with several hidden layers, each containing a varying number of neurons. We use the ReLU activation function to introduce non-linearity and ensure the model's ability to capture complex relationships. Dropout layers are incorporated to prevent overfitting and improve generalization.
We compile the ANN using the Adam optimizer and the binary cross-entropy loss function. We train the model using the preprocessed dataset, splitting it into training and validation sets. The model is trained for a specific number of epochs, with a defined batch size.
Throughout the training process, we monitor the model's performance using metrics such as loss and accuracy on both the training and validation sets. We make use of early stopping to prevent overfitting and save the best model based on the validation performance. Once the ANN is trained, we evaluate its performance on a separate test set. We calculate metrics such as accuracy, precision, recall, and F1-score to assess the model's predictive capabilities in identifying loan default risk.
In conclusion, this project involves the exploration of a loan dataset, preprocessing of the data, and the application of various machine learning models and a deep learning ANN to predict the risk flag for loan default. The machine learning models, including logistic regression, decision trees, SVM, and ensemble methods, provide insights into feature importance and achieve reasonable predictive performance. The deep learning ANN, with its ability to capture complex relationships, offers the potential for improved accuracy in predicting loan default risk. By combining these approaches, we can assist financial institutions in making informed decisions and managing loan default risks more effectively.














No comments:
Post a Comment